Why Instant NGP is extremely fast?
Neural Graphics Primitives (NGP) is an object represented by quires to a neural network.
Instant NGP speeds up the training of the original NeRF by 1000x, while still using neural network to implicitly store the scene. What is the magic in it?
Trainable Multiresolution Hash Encoding
The trainable multiresolution hash encoding permits the use of a smaller neural network without sacrificing quality, and remains generality. Several techniques are used to make the encoding works better on modern GPU.
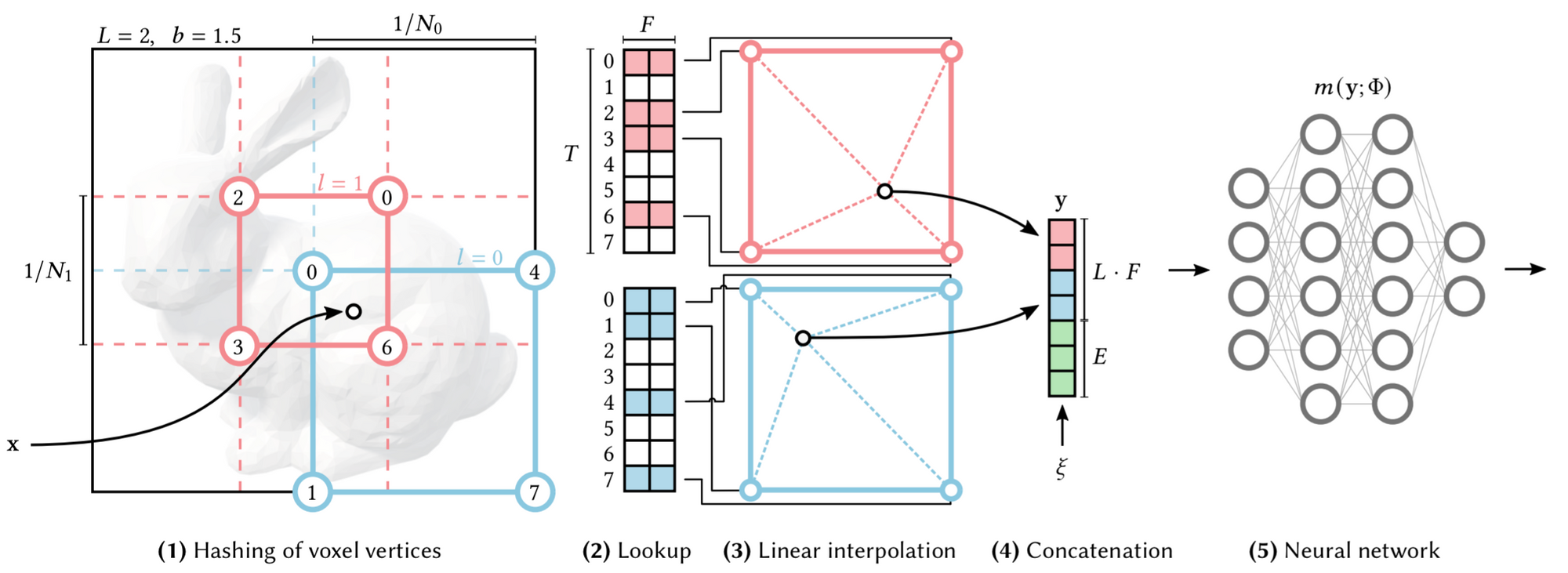
The trainable features are arranged into $L=16$ levels of hash tables, each mapped to one resolution of a virtual 3D voxel grid. Given a 3D location $(x,y,z)$, on each level of 3D voxel grid, we interpolate the feature vectors from the feature vectors of its 8 integer corners (4 corners if 2D, as shown in the picture). All feature vectors ($F$ dimension) of all these integer corners are stored in a static data structure, i.e. the hash table of size $T$. So for each location we're interested, at each $L$ level, we lookup hash table for 8 times, and interpolate to get a feature vector of size $F$. Then we concatenate all feature vectors of all levels with a auxiliary feature vector (can be anything!) of size $E$. Finally, we get a feature vector of size $(L\times F + E)$.
To be notice, this process can be done in parallel efficiently. For every pixels we try to render at a time, we load one level of the hash table into the GPU cache, do the hash, look-up the feature vectors of all these pixels, then interpolate. Then move on to the next level, do the same thing. Finally, all the interpolated features are concatenated together, along with a auxiliary input, becomes the input of the neural network.
The efficiency of the static hash table is better than dynamic structures like tree, and it is more general. When the resolution of a certain level is larger than the hash table size, there will be hash collision. But it is automatically solved by multi-resolution and interpolation. (The chance that 2 different location has the same final feature vector input is near zero)
The proposed hash encoding is highly efficient and is tailored with several techniques to improve even more.
Mixed-precision
The hash table entries are stored in half-precision, and mixed precision training were used. That enables faster training and faster inference.
GPU Cache Optimization
As mentioned before, the hash tables are evaluated level by level. So only some levels of the hash tables will reside in caches and will be reused over and over again, at any given time.
More importantly, the use of the multiresolution hash encoding makes it possible to use a smaller neural network without sacrificing quality.
Smaller Neural Networks (Fully-fused MLPs)
Instant NGP uses highly optimized fully-fused MLP, which is 5-10x faster than TensorFlow implementation (e.g. in original NeRF).
By using a relatively small neural network, and make good use of the GPU, instant NGP gets their neural network part close to voxel lookup speed.
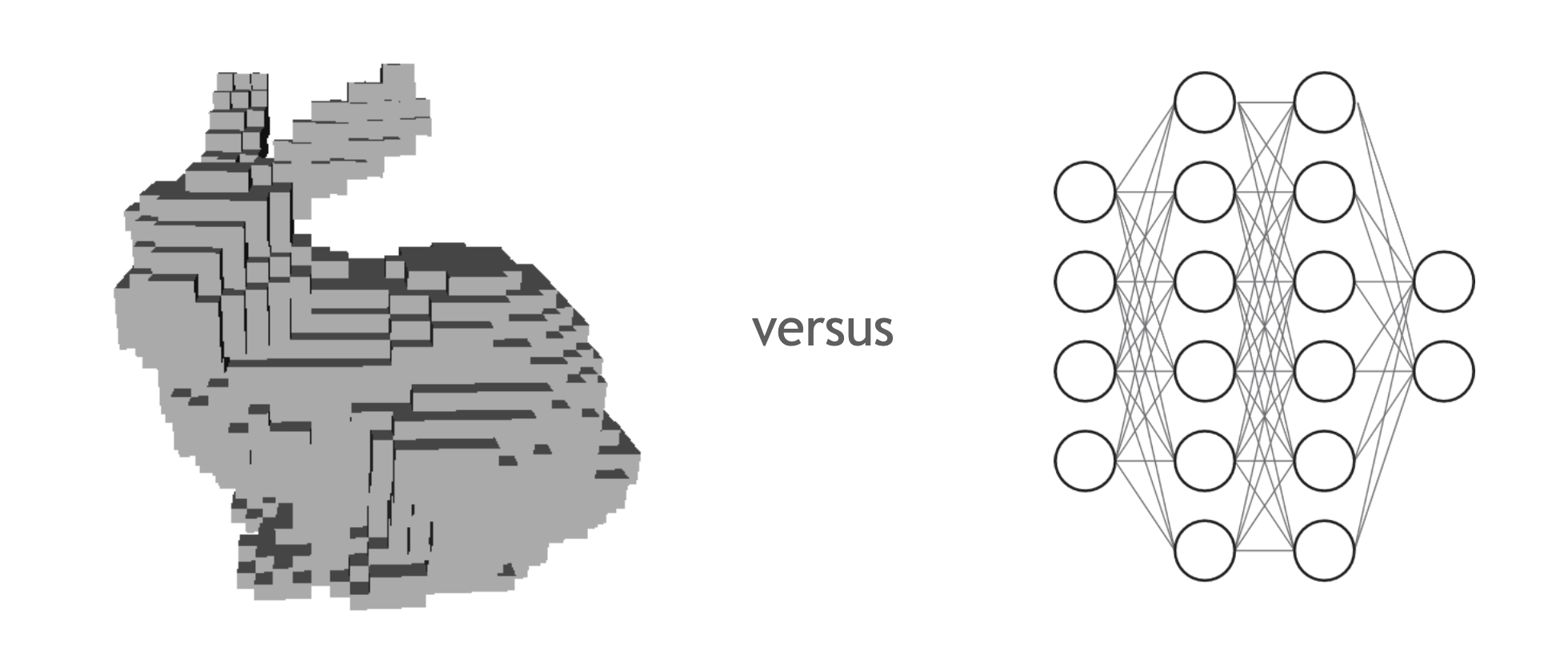
Voxel based method stores the scene 3D voxels, like store image data in 2D pixels. To know the attribute of a given position (3D coordinates), a simple look-up is enough. Methods like Plenoxels uses voxels in replace of neural network to significantly speedup the pipeline. But to store a high-resolution scene, excess memory are needed. That amount of storage makes a simple look-up not simple anymore. When training, huge amount of the voxel data are needed to be transferred into memory and cache repeatedly. Excess memory operations bound the speed (but it is still relatively fast).
Theoretically, voxel based method can be faster when we have more memory and cache. And neural network based method trades the memory footprint for compute. It can be faster if we make the computation more effectively.
For a standard neural network, given a fixed batch size, the compute cost is $O(M)$, and memory cost is $O(M^2)$, while $M$ is number of neurons per layer. On bigger neural networks, focus on optimization of computation is wise, but on smaller ones, the memory is the most important thing.
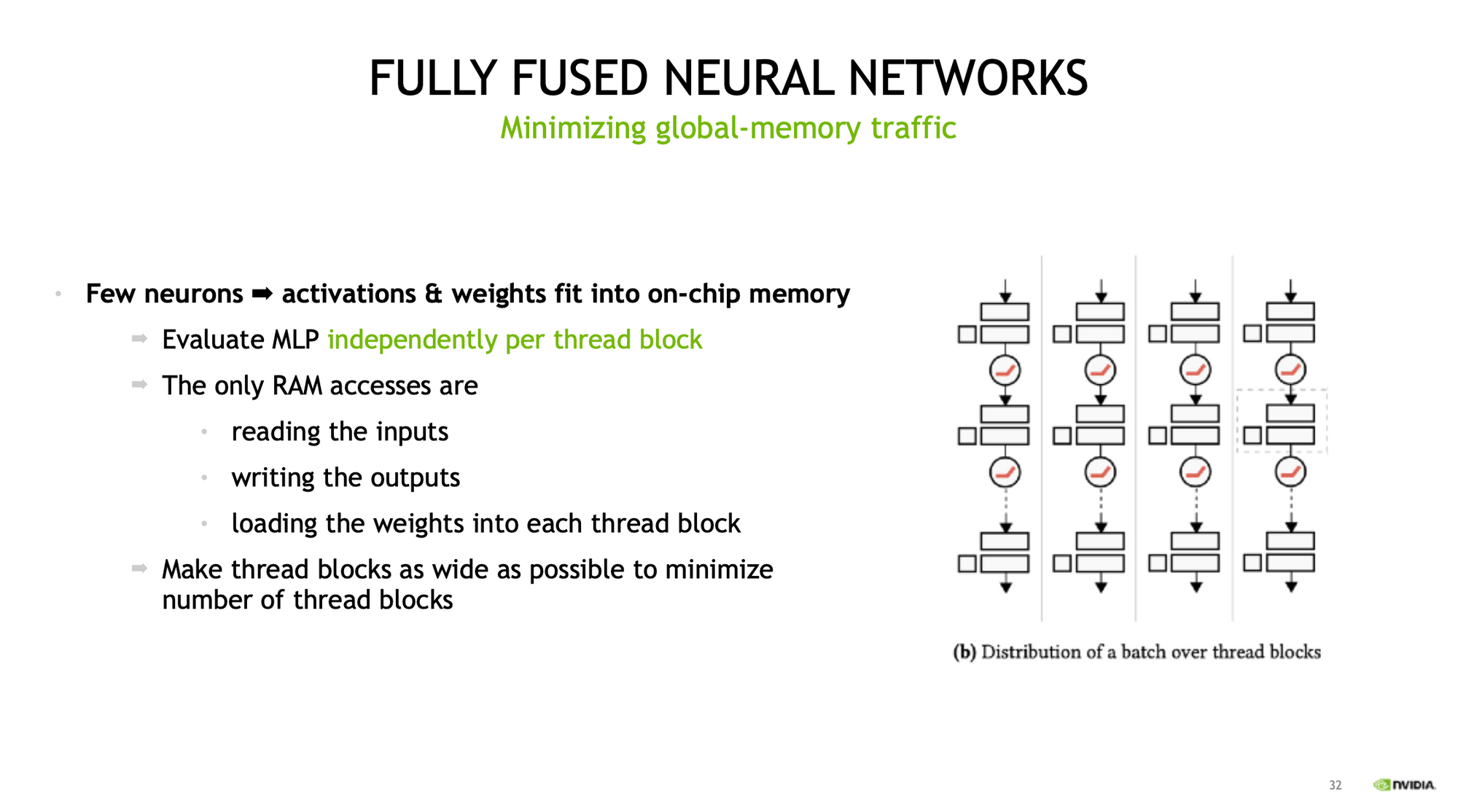
They made their neural network so small, so that the whole network can fit into the on-chip memory of the GPU. When evaluating the network (imagine ray marching and query thousands of vales at the same time), each thread block can run the whole network independently, using the weights and bias stored in on-chip memory.
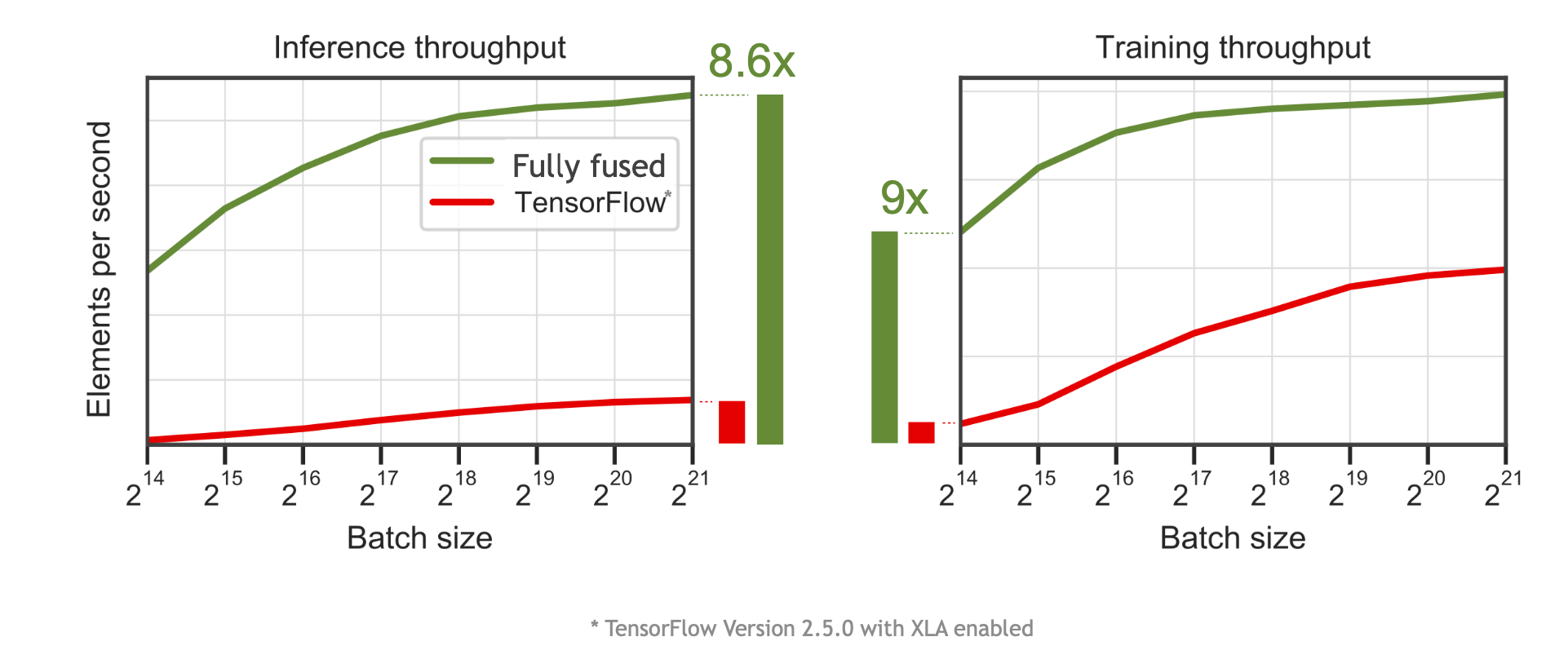
The authors are from NVIDIA, they know their hardware well, and they know CUDA well, so they implemented instant NGP in CUDA and integrated with fully-fused MLPs of the tiny-cuda-nn framework. With carefully tailored neural network and good use of the NVIDIA GPU, 5-10x speedup is achieved compared with TensorFlow version.
Accelerated Ray Marching
Overall, instant NGP takes 10-100x fewer steps than the naïve dense stepping, which means 10-100x fewer less query of the neural network.
- Exponential stepping for large scenes.
- Skipping of empty space and occluded regions.
- Compaction of samples into dense buffers for efficient execution.
Exponential stepping for large scenes
Typically, larger scenes have more empty regions, and coarser details is not too noticeable. A exponential step size is so the computation grows with scene size.
Skipping of empty space and occluded regions
A multi-scale occupancy grid is maintained to indicate where in the space is empty. For empty spaces we don't have to infer the neural network, hence computation is saved. (little extra memory but less computation)